
Table of Links
-
Materials and Methods
2.1 Vector Database and Indexing
-
Discussion
4.1 Dataset and 4.2 Re-ranking
4.4 Volume-based, Region-based and Localized Retrieval and 4.5 Localization-ratio
4 Discussion
4.1 Dataset
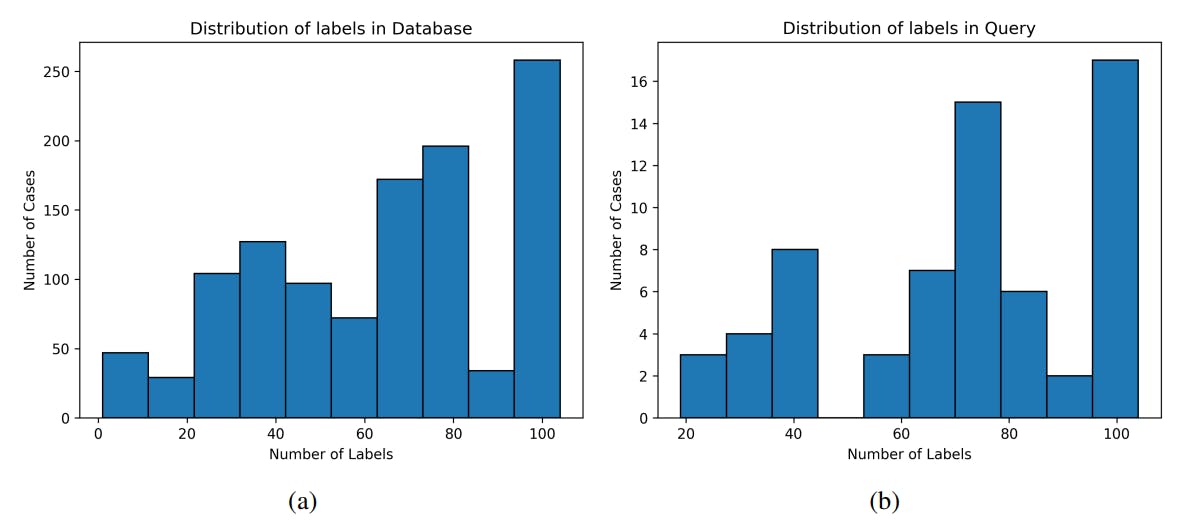
As depicted in Figure 6, the labels inside the database and query subset (derived from TS train and test set, respectively) are not balanced. This should resemble a pattern as can be observed in future real-world scenarios of image retrieval. At the same time, this imbalance should be kept in mind when reading and interpreting recall values from the provided result tables.
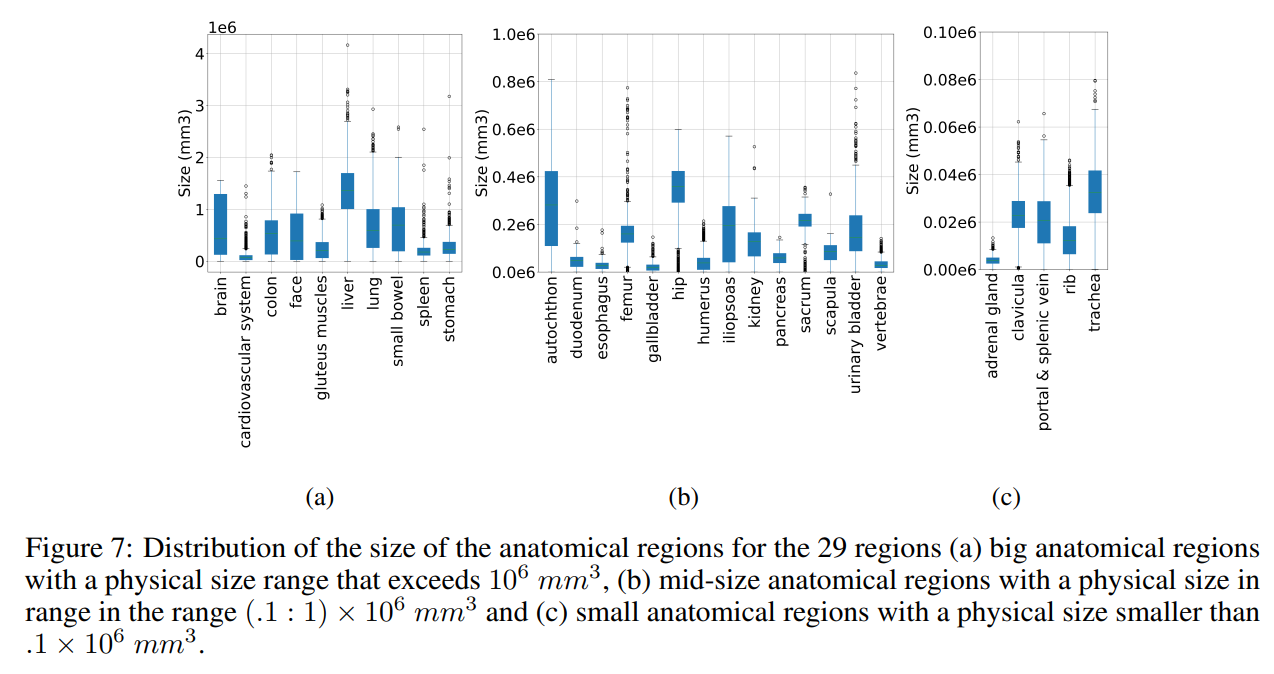
Additionally, it is worth noting that the size and shape of organs can impact the probability of correctly predicting a given label by chance. For example, smaller organs can be less likely to collect "by-chance" true positive predictions compared to larger organs. Similarly, organs with elongated shapes aligned with the slice-wise sampling direction can increase the likelihood of "by-chance" hits. A volume and shape-adjusted representation of recall values does not seem reasonable and thus has not been performed in this work. However, organ volume as shown in Figure 7 and Figure 8 should be considered while interpreting result tables.
Figure 9 and Figure 10 present an overview of mean recall for each of the retrieval methods (all models) versus the mean anatomical region size for 29 and 104 classes, respectively. There is no pattern suggesting any correlation between the size of the anatomical region and the average retrieval recall.
4.2 Re-ranking
For the first time, we could successfully adopt and show the feasibility of ColBERT-inspired re-ranking for an image retrieval task. In theory, this shows that CBIR results can be made subject to context-aware re-ranking. This is very important as it provides a conceptual entry point to use the information of a future retrieval solution in the real world. Concretely, observations such as user behavior on a graphical user interface, and temporal or medical relevance can be "factored in" to adjust the search results. Further research will study the advantages and disadvantages of ColBERT-inspired re-ranking. In future works, further insights into balancing computational costs in the context of latency-accuracy trade-offs will be shared.
Authors:
(1) Farnaz Khun Jush, Bayer AG, Berlin, Germany ([email protected]);
(2) Steffen Vogler, Bayer AG, Berlin, Germany ([email protected]);
(3) Tuan Truong, Bayer AG, Berlin, Germany ([email protected]);
(4) Matthias Lenga, Bayer AG, Berlin, Germany ([email protected]).
This paper is