

Authors:
(1) Ning Wang, Huawei Inc.;
(2) Jiangrong Xie, Huawei Inc.;
(3) Hang Luo, Huawei Inc.;
(4) Qinglin Cheng, Huawei Inc.;
(5) Jihao Wu, Huawei Inc.;
(6) Mingbo Jia, Huawei Inc.;
(7) Linlin Li, Huawei Inc.;
Table of Links
3 Methodology and 3.1 Model Architecture
4 Experiments
4.1 Datasets and Metrics and 4.2 Implementation Details
4.4 Inference on the Mobile Device and 4.5 State-of-the-art Comparison
A Implementation Details
A.1 Training Details

As for the visual concept number, we empirically set K = 20 to select top-K concepts for efficient cross-modal fusion. We observe that the performance will slightly drop when the concept number is less than 15. Our visual concept extractor is trained on the VG dataset (Krishna et al. 2017), which is widely used in the image captioning task.
A.2 Evaluation on the Mobile Device
In this work, we test the inference latency of LightCap model on the mobile phone Huawei P40. The testing chip on Huawei P40 mobile phone is Kirin 990[1]. The detailed inference speeds of the components in LightCap are shown in Table 7. To purely investigate the model inference speed, we set the beam search size to 1. The memory usage is 257 MB on the mobile phone. It merely takes about 188ms for our light model to process a single image on the CPU from mobile devices, which meets the real-world efficiency requirements. It is well recognized that leveraging the NPU or GPU on mobile devices can achieve a higher inference speed, while not all the mobile devices are equipped with a strong chip. Consequently, we utilize the CPU in Kirin 990 to test our method (188ms per image). The inference latency on the PC with a Titan X GPU is about 90ms.
B Visualization Results
B.1 Visualization of Visual Concept Extractor
We visualize the image concept retrieval results in Figure 4. In the second column, we exhibit the foreground detection

results of the tiny detector YOLOv5n. Although this detector is relatively weak and fails to outperform the state-of-theart two-stage detection methods, it is extremely light with only 1.9M parameters. Besides, accurate bounding boxes are not necessary for our framework. Based on the roughly predicted foreground ROIs, we focus on retrieving visual concepts of the image. As shown in the third column, our visual concept extractor is able to predict accurate and dense object tags to form the image concept.

B.2 Visualization of Cross-modal Modulator
In Figure 5, we further visualize the channel attentions of the retrieved visual concepts. For the given image in Figure 5, the first three visual concepts are Dessert, Cake, and Spoon. These visual concepts are projected to the channel attentions to modulate the raw CLIP features. As shown
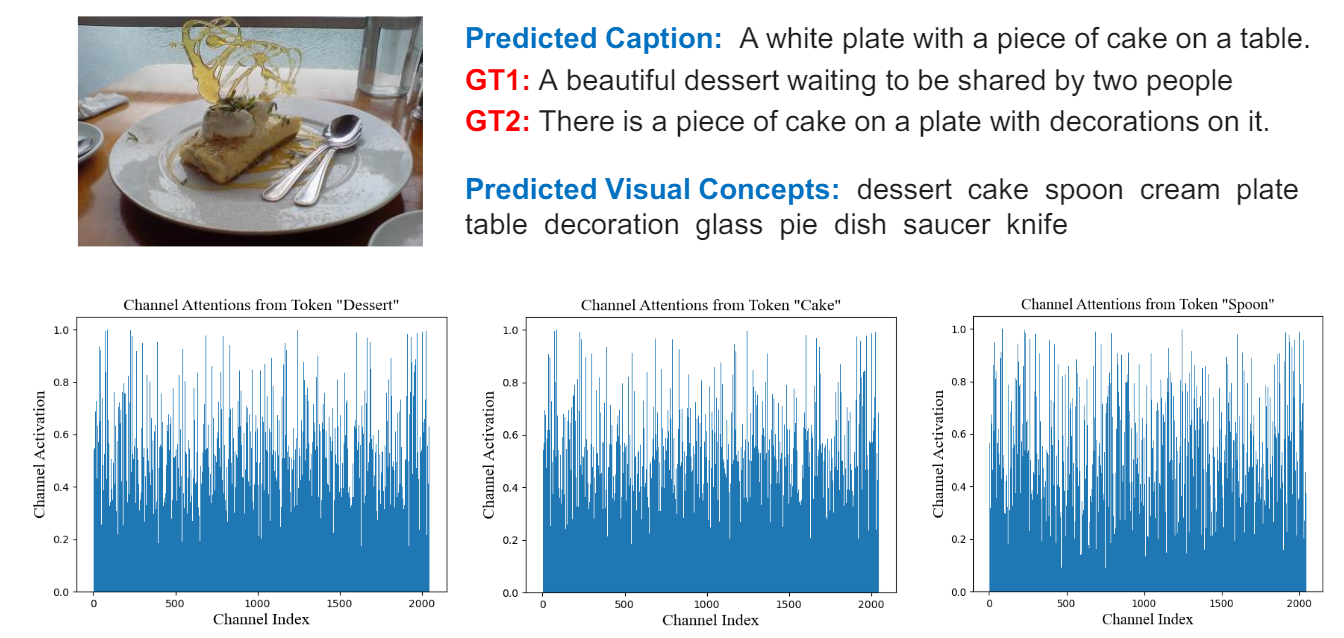

in the bottom figures in Figure 5, the activated channels are sparse (i.e., only a few channels yield the high attention values of more than 0.8) and most channel weights are below 0.5. This verifies our assumption that the raw CLIP features are redundant in the channel dimension. Besides, the channel attentions from Dessert and Cake are similar, potentially due to their high similarity in the semantic space. However, the attention weight generated by Spoon is quite different from the attentions of Dessert and Cake. It is well recognized that different feature channels represent certain semantics, and our approach is able to activate the informative channels using the retrieved concepts for effective image captioning.
B.3 Qualitative Evaluation
Finally, we exhibit the captioning results of our approach on the COCO-caption dataset (Karpathy and Fei-Fei 2015) in Figure 6, coupled with ground truth (GT) sentences. Figure 6 also showcases the results of the state-of-the-art OscarB method (Li et al. 2020b). Overall, on these uncurated images from the COCO Karpathy test set, our LightCap generates accurate captions and is comparable with the strong OscarB. The proposed approach even yields more accurate captions than OscarB in the third picture, where OscarB predicts woman instead of man. It should be noted that such a robust model achieves promising results by retaining only 2% FLOPs of the current state-of-the-art captioners.
This paper is available on arxiv under CC BY 4.0 DEED license.
[1] https://www.hisilicon.com/en/products/Kirin/Kirin-flagshipchips/Kirin-990