

Authors:
(1) Ning Wang, Huawei Inc.;
(2) Jiangrong Xie, Huawei Inc.;
(3) Hang Luo, Huawei Inc.;
(4) Qinglin Cheng, Huawei Inc.;
(5) Jihao Wu, Huawei Inc.;
(6) Mingbo Jia, Huawei Inc.;
(7) Linlin Li, Huawei Inc.;
Table of Links
3 Methodology and 3.1 Model Architecture
4 Experiments
4.1 Datasets and Metrics and 4.2 Implementation Details
4.4 Inference on the Mobile Device and 4.5 State-of-the-art Comparison
C Results on Nocaps
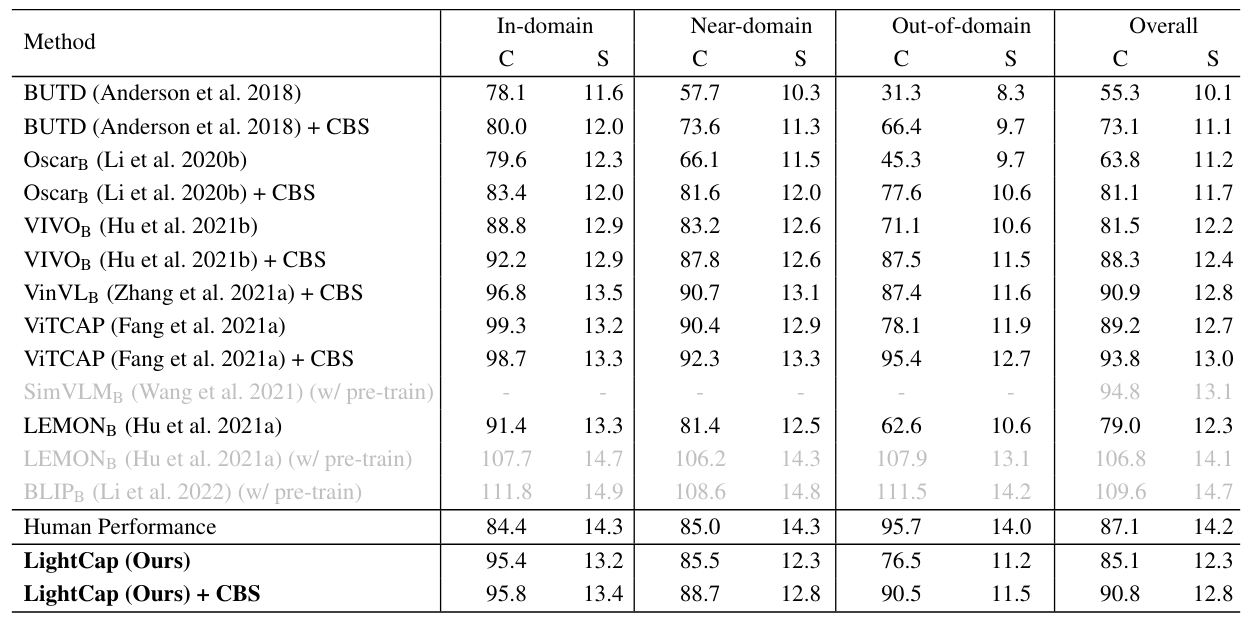
Due to the limited space, we only exhibit “out-of-domain” and “overall” comparison results on the Nocaps dataset (Agrawal et al. 2019) in the main paper. In Table 8 of this supplementary material, we show the complete results including “in-domain”, “near-domain”, “out-of-domain”, and “overall” performance.
D Limitations and Future Work
Despite the super-balanced performance and efficiency, the proposed framework still has some limitations:
(1) Training a More Efficient CLIP. The main computational cost of our work lies in the visual backbone (i.e., ResNet-50). In the future, we plan to train an EfficientNet-based CLIP model to further reduce the feature extraction latency of the visual encoder.
(2) End-to-end Training. Currently, we freeze the model parameters of the CLIP ResNet-50 backbone. We observe that end-to-end training of the visual backbone will degrade the performance, potentially due to the limited training data in the image captioning domain. In the future, we intend to include more data to facilitate the joint training of the visual backbone and fusion model.
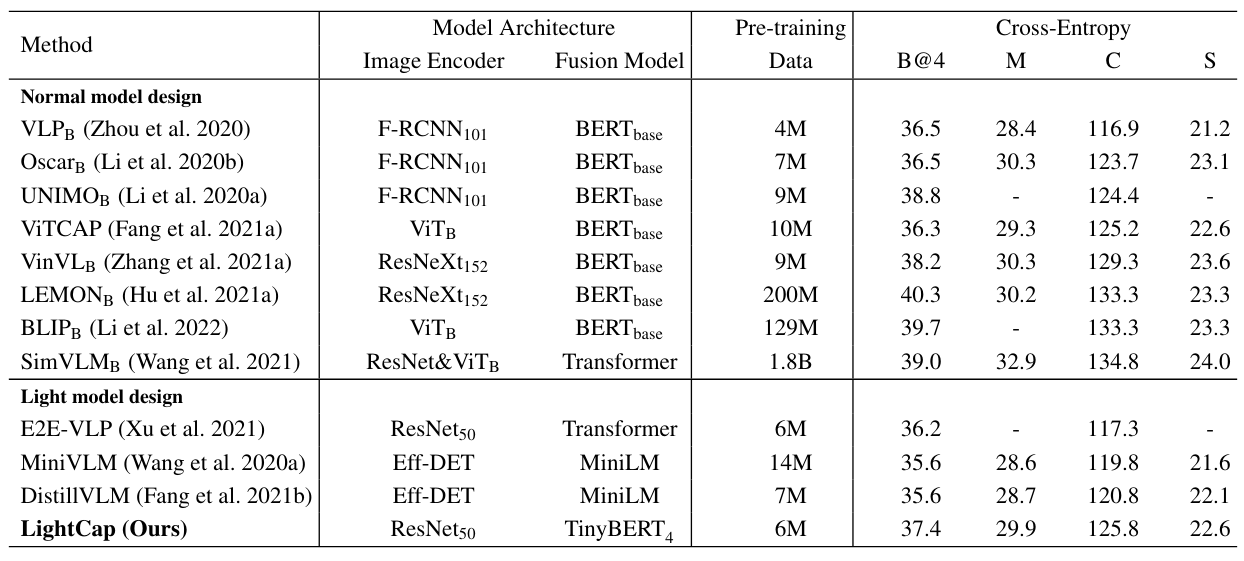
(3) Adding More Pre-training Data. Although our approach adopts the cross-modal pre-training, as shown in Table 9, our pre-training data is much less than the recent LEMON (Hu et al. 2021a), BLIP (Li et al. 2022), and SimVLM (Wang et al. 2021). In the future, we plan to involve more pre-training data to boost the captioning quality.
This paper is available on arxiv under CC BY 4.0 DEED license.