

Authors:
(1) Ning Wang, Huawei Inc.;
(2) Jiangrong Xie, Huawei Inc.;
(3) Hang Luo, Huawei Inc.;
(4) Qinglin Cheng, Huawei Inc.;
(5) Jihao Wu, Huawei Inc.;
(6) Mingbo Jia, Huawei Inc.;
(7) Linlin Li, Huawei Inc.;
Table of Links
3 Methodology and 3.1 Model Architecture
4 Experiments
4.1 Datasets and Metrics and 4.2 Implementation Details
4.4 Inference on the Mobile Device and 4.5 State-of-the-art Comparison
3 Methodology
In this section, we introduce the technical details of the proposed method. First, in Section 3.1, we elaborate on the model design of each block. Then, in Section 3.2, we show the training details. Finally, we exhibit the model distillation in both pre-training and fine-tuning stages in Section 3.3.
3.1 Model Architecture
The overall framework is shown in Figure 2. Our LightCap contains an image encoder to extract the visual representations, a concept extractor to retrieve the visual concepts from an off-the-shelf vocabulary, and a cross-modal modulator to enhance the visual representations with the textual (concept) information. Finally, we use a lightweight TinyBERT to fuse multi-modal representations and an ensemble head module to generate the image caption.
Image Encoder. Instead of extracting expensive ROI features from object detectors, we leverage the ResNet backbone (He et al. 2016) to acquire grid representations. Specifically, we choose the recent CLIP model (ResNet-50 version) (Radford et al. 2021) due to (1) its impressive generalization capability, especially in the cross-modal domain; (2) its promising potential in extracting visual concepts from images, which is beneficial to the image captioning task. CLIP model contains a visual encoder and a text encoder. In the visual encoder, after obtaining the image feature map, CLIP additionally learns a transformer block (i.e., attention pooler) to obtain the global image embedding. In our framework, to save the model capacity, we only utilize the ResNet50 backbone in CLIP visual encoder without the attention pooler to extract the visual features v ∈ R 7×7×2048, which only involves 4.1G FLOPs.
Visual Concept Extractor. Intuitively, knowing the semantic concepts of the image is highly beneficial to image captioning. Although CLIP model is ready for cross-modal retrieval, there still exist two issues. First, CLIP relies on a heavy attention pooler to obtain the global image representation, which contains 14.8M parameters and is in conflict with our lightweight model design. Second, CLIP model is pre-trained using global image features and thus is not effective enough in recognizing image regions. To this end, we design and train an efficient region-based visual concept extractor on top of the CLIP feature.
The overall architecture of the proposed visual concept extractor is shown in Figure 3 (left). First, we collect the common object categories from the Visual Genome dataset (Krishna et al. 2017), and form these category words using the description form a photo of [object]. We take advantage of the CLIP text encoder to extract the textual embeddings of these descriptions to form an off-the-shelf vocabulary. Note that this vocabulary contains textual embeddings instead of the raw words to avoid unnecessary computations in the captioning stage. Then, we train an efficient foreground-background object detector without knowing object classes. This detector is designed to roughly predict the foreground bounding boxes, whose architecture is tiny YOLOv5n (Ultralytics 2020) with only 1.9M parameters. After obtaining the object proposals, we employ ROIAlign (He et al. 2017) to pool the region embeddings. These ROI embeddings are further processed by two linear blocks to align with the concept embeddings in the aforementioned vocabulary. To train this concept extractor, we freeze the CLIP ResNet-50 parameters and only train two linear layers using the standard contrastive loss in CLIP.
In summary, compared to the original CLIP, we transfer it from global image-text retrieval to region-level content retrieval. In the image captioning stage, for each foreground proposal, the object category with the highest similarity score is assigned as its label. All the retrieved labels are assembled to form the visual concept of the image.

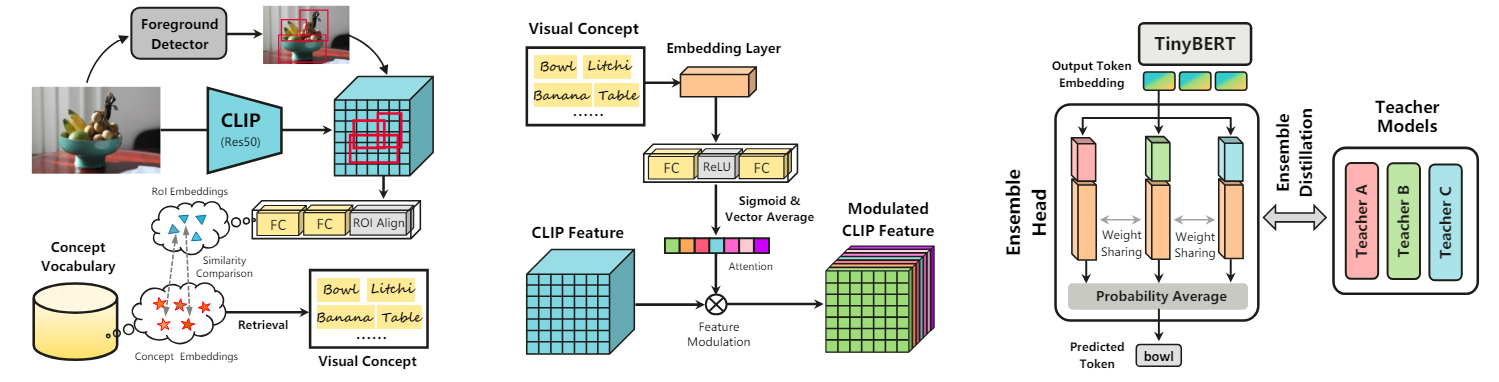
Multi-modal Fusion Module. The proposed method adopts TinyBERT4 (Jiao et al. 2019) as the cross-modal fusion module, which is extremely shallow consisting of only 4 transformer blocks and a hidden size of 312.

Ensemble Head Module. Multi-model ensemble is an intuitive way to improve the performance, but will greatly increase the model size. In this work, we propose a parameterefficient ensemble head to predict the token. The ensemble head contains three branches to parallelly tackle the word embeddings, as shown in Figure 3 (right). We recognize that the parameter burden of head network mainly resides in the word embedding layer, whose shape is 312 × 30522 (dictionary size). To reduce the storage room, word embedding layers in different branches share the model weights, while the lightweight project layers (shape: 312 × 312) before the word embedding layer are individually optimized for diversity. These parallel head networks are individually distilled by different teacher networks to further enhance the prediction diversity, which will be discussed in the next section.
3.2 Model Training

3.3 Knowledge Distillation


Ensemble KD. Actually, instead of adopting a single head, we construct the ensemble head with three parallel branches. We train three teacher models with different model initializations. These teachers jointly distill different branches of the ensemble head model, as shown in Figure 3 (right).
This paper is available on arxiv under CC BY 4.0 DEED license.