

Authors:
(1) Ning Wang, Huawei Inc.;
(2) Jiangrong Xie, Huawei Inc.;
(3) Hang Luo, Huawei Inc.;
(4) Qinglin Cheng, Huawei Inc.;
(5) Jihao Wu, Huawei Inc.;
(6) Mingbo Jia, Huawei Inc.;
(7) Linlin Li, Huawei Inc.;
Table of Links
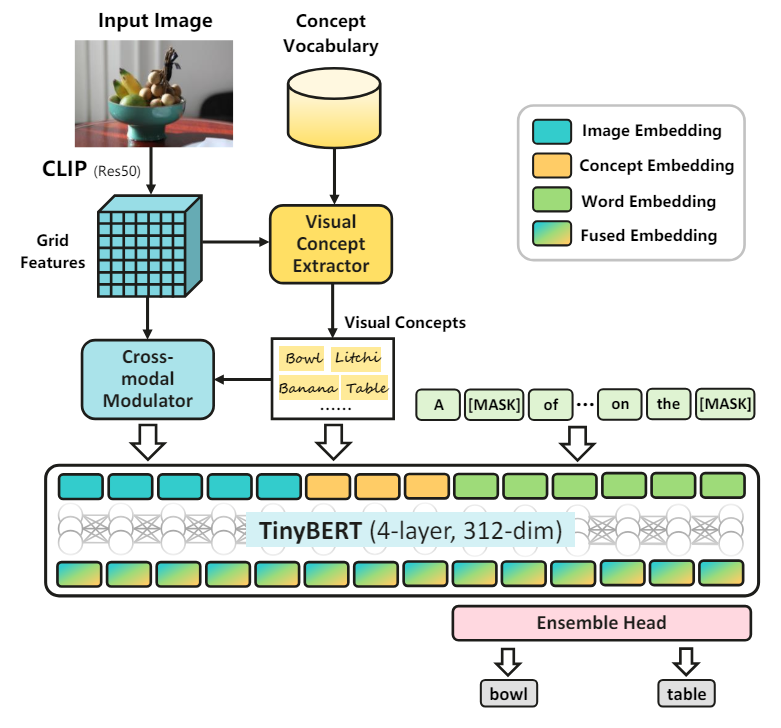
3 Methodology and 3.1 Model Architecture
4 Experiments
4.1 Datasets and Metrics and 4.2 Implementation Details
4.4 Inference on the Mobile Device and 4.5 State-of-the-art Comparison
2 Related Work
Image Captioning. Image captioning methods generally contain a visual encoder to extract the image representations and a cross-modal fusion model to generate the caption. Previous methods (Huang et al. 2019; Pan et al. 2020; Anderson et al. 2018; Ji et al. 2021; Song et al. 2021; Fei 2022; Yang, Liu, and Wang 2022) typically utilize the object detection methods such as Faster-RCNN (Ren et al. 2016) to extract ROI features. The recent VinVL method (Zhang et al. 2021a) shows that a strong visual feature extractor consistently improves the performance on image captioning.
To reduce the computational burden, MiniVLM (Wang et al. 2020a) designs a lightweight object detector using EfficientNet backbone (Tan and Le 2019). DistillVLM (Fang et al. 2021b) leverages knowledge distillation to acquire a thinner transformer architecture for vision-language tasks. In contrast to the ROI features from object detectors, some cross-modal algorithms turn to the grid features for high efficiency, which are known as the detector-free approaches in the literature (Fang et al. 2021a; Xu et al. 2021; Wang et al. 2021; Wang, Xu, and Sun 2022). Nevertheless, these models (Fang et al. 2021a; Wang et al. 2021; Wang, Xu, and Sun 2022) still struggle to be deployed on edge devices. Compared with them, our method leverages a light yet powerful CLIP model to extract the grid features. We further propose a concept extractor and a cross-modal modulator to unveil the cross-modal representation power of the CLIP. Our approach outperforms previous efficient captioners such as MiniVLM (Wang et al. 2020a) and DistillVLM (Fang et al. 2021b) with lower model capacity and faster inference speed, and is even comparable to the recent heavyweight captioners.
Recent works (Shen et al. 2021; Cornia et al. 2021) also take advantage of CLIP model for image captioning. Nevertheless, they simply utilize the standard CLIP model to extract features or image tags. In contrast, to reduce the model size, we train a lightweight region-level concept extractor as well as a feature modulator to better exploit the cross-modal characteristic of CLIP.
VL Pre-training. Vision-language (VL) pre-training aims to learn robust cross-modal representations to bridge the domain gap between vision and language signals (Dou et al. 2021). CLIP (Radford et al. 2021) and ALIGN (Jia et al. 2021) align the VL representations via a light fusion manner (i.e, dot-product) using the contrastive learning technique. Nevertheless, their light fusion manner fails to conduct the cross-modal generation task such as image captioning. In contrast, recent VL pre-training approaches (Zhou et al. 2020; Chen et al. 2020; Li et al. 2020b,a; Zhang et al. 2021a) adopt a relatively heavy transformer architecture (Vaswani et al. 2017) to fuse the VL representations, which are qualified to perform more VL downstream tasks. Inspired by previous arts, our approach also involves VL pre-training to facilitate the downstream captioning task. Differently, we do not employ the widely-adopted bidirectional masked language modeling, and shed light on the unidirectional language modeling to fully focus on the text generation task, e.g., image captioning. Furthermore, similar to previous arts (Jiao et al. 2019; Mukherjee and Awadallah 2020), we adopt the sequential knowledge distillation (KD) to preserve the model representational capability within a tiny network. Based on the general KD, we also investigate how to better leverage KD in the captioning task by introducing concept distillation to facilitate the modality alignment and ensemble distillation for multi-head optimization.
This paper is available on arxiv under CC BY 4.0 DEED license.