

Authors:
(1) Ning Wang, Huawei Inc.;
(2) Jiangrong Xie, Huawei Inc.;
(3) Hang Luo, Huawei Inc.;
(4) Qinglin Cheng, Huawei Inc.;
(5) Jihao Wu, Huawei Inc.;
(6) Mingbo Jia, Huawei Inc.;
(7) Linlin Li, Huawei Inc.;
Table of Links
3 Methodology and 3.1 Model Architecture
4 Experiments
4.1 Datasets and Metrics and 4.2 Implementation Details
4.4 Inference on the Mobile Device and 4.5 State-of-the-art Comparison
Abstract
Recent years have witnessed the rapid progress of image captioning. However, the demands for large memory storage and heavy computational burden prevent these captioning models from being deployed on mobile devices. The main obstacles lie in the heavyweight visual feature extractors (i.e., object detectors) and complicated cross-modal fusion networks. To this end, we propose LightCap, a lightweight image captioner for resource-limited devices. The core design is built on the recent CLIP model for efficient image captioning. To be specific, on the one hand, we leverage the CLIP model to extract the compact grid features without relying on the time-consuming object detectors. On the other hand, we transfer the image-text retrieval design of CLIP to image captioning scenarios by devising a novel visual concept extractor and a cross-modal modulator. We further optimize the cross-modal fusion model and parallel prediction heads via sequential and ensemble distillations. With the carefully designed architecture, our model merely contains 40M parameters, saving the model size by more than 75% and the FLOPs by more than 98% in comparison with the current state-of-the-art methods. In spite of the low capacity, our model still exhibits state-of-the-art performance on prevalent datasets, e.g., 136.6 CIDEr on COCO Karpathy test split. Testing on the smartphone with only a single CPU, the proposed LightCap exhibits a fast inference speed of 188ms per image, which is ready for practical applications.
1 Introduction
Image captioning aims to automatically generate natural and readable sentences to describe the image contents, which provides a promising manner to help visually impaired people. The recent decade has witnessed a surge of captioning algorithms, benefiting from the development of large-scale pre-training (Zhou et al. 2020; Li et al. 2020b; Hu et al. 2021a; Wang et al. 2021), advanced representation learning (Zhang et al. 2021a; Huang et al. 2021), and modern crossmodal modeling (Xu et al. 2021; Li et al. 2020b; Fang et al. 2021a). In spite of the remarkable advances, current heavyweight captioning algorithms are not available to visually impaired people, who generally rely on low-resource devices such as portable phones to assist the daily life, instead of carrying on heavy computer servers with modern GPUs.
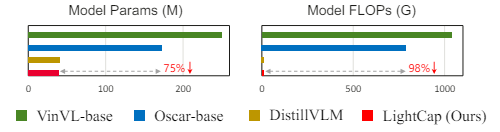
Designing computationally efficient and memory-friendly captioning methods is vital for practical applications but has been largely overlooked in the literature.
To achieve excellent performance, recent image captioners typically adopt deep object detectors as well as large cross-modal fusion networks. For example, the recent VinVL and LEMON algorithms (Zhang et al. 2021a; Hu et al. 2021a) utilize a strong but heavyweight ResNeXt-152 based detection model and a base or large BERT model (Devlin et al. 2018). Some methods even scale the model size from base to huge to attain superior captioning performance (Hu et al. 2021a), but how to effectively reduce the model size for edge devices is rarely touched in these works. These sophisticated image captioning models struggle to meet the real-time requirement of real-world applications, let alone the huge power consumption and memory storage. It is therefore non-trivial to investigate how to design an efficient image captioner with smaller memory storage, faster inference speed, and satisfactory performance.
In this paper, we propose LightCap, a lightweight yet high-performance image captioning method for mobile devices. Our core design is largely inspired by the recent CLIP method (Radford et al. 2021). CLIP is an impressive imagetext retrieval model, which readily tells what objects exist in the image but fails to generate a description for the given image. In this work, we investigate how to transfer such a strong cross-modal retrieval model to an image captioner, and meanwhile break the obstacles that hinder image captioners from being deployed on the mobile devices. The main obstacles that hinder image captioners from be ing deployed on mobile devices are their cross-modal fusion and image feature extraction models. For visual representations, we leverage the efficient yet compact grid features from the CLIP without relying on time-consuming Region of Interest (ROI) features from sophisticated object detectors. To unveil the potential of a capacity-limited model, we propose the following designs. (1) Visual concept extractor. To take advantage of the cross-modal retrieval capability of CLIP, we train a region-based alignment model to retrieve the visual concepts from an off-the-shelf dictionary. These visual concepts serve as the description hints of the image to facilitate caption generation. (2) Cross-modal modulator. Before being fed to the fusion model, the feature dimension of the CLIP feature is highly compressed (i.e., from 2048 to 312), which inevitably loses semantic representations. To retain the valuable semantics, we propose a crossmodal modulator that takes the textual concepts as inputs to activate the informative feature channels of the CLIP model. (3) Ensemble head. We jointly optimize and distill an ensemble of head networks for collaborative prediction. We disentangle the key parameters and share the rest weights of different heads for lightweight design. Last but not least, for the cross-modal fusion model, instead of the widelyused BERTbase (Devlin et al. 2018), we chose the efficient TinyBERT (Jiao et al. 2019) to fuse cross-modal features. By virtue of our designed sequential knowledge distillations in both pre-training and fine-tuning stages and the ensemble distillations from multiple teachers, a TinyBERT almost matches the performance of the standard BERT.
By highly limiting the capacity of each component in our image captioner, the overall model merely contains 40M parameters and 9.8G FLOPs, saving the model size by more than 75% and the FLOPs by more than 98% compared to the current popular image captioning models (Figure 1). Despite its low capacity, the proposed method still exhibits state-ofthe-art performance on prevalent captioning datasets, e.g., 136.6 CIDEr on COCO Karpathy split (Lin et al. 2014). The model storage memory of LightCap is about 112MB, which is affordable on most mobile devices. It merely costs about 188ms to process an image when testing the proposed LightCap on the mobile phone with only one CPU, which is readily ready for practical usage.
In summary, in this paper, we systematically show how to obtain a lightweight, efficient, and high-performance captioner by careful designs and training:
• Model Design. We propose a visual concept extractor and a cross-modal modulator to better exploit the crossmodal capability of the CLIP model for image captioning. We further design a partially parameter-sharing ensemble head for collaborative prediction.
• Model Training. We present the sequential knowledge distillations from pre-training to fine-tuning to distill the tiny model. We leverage the ensemble distillation to better optimize the TinyBERT model and ensemble heads.
This paper is available on arxiv under CC BY 4.0 DEED license.