

These Tiny Bees Just Changed the Way We Think About AI Models
1 Sept 2025
Learn how an excellent replacement for re-id, retro-identification, allows researchers to more effectively examine reed bees and other species throughout time

A New Era of Markerless Insect Tracking Technology Has been Unlocked by Retro-ID
1 Sept 2025
Learn about retro-ID, a cutting-edge AI-powered technique that goes beyond re-identification in insect research by identifying and tracking insects backwards.

Why Retro-Identification Is the Key to Efficient Behavioural Research in Animals
1 Sept 2025
Discover how retro-identification increases the effectiveness of animal behavior research, reducing wasted annotation and boosting accuracy.
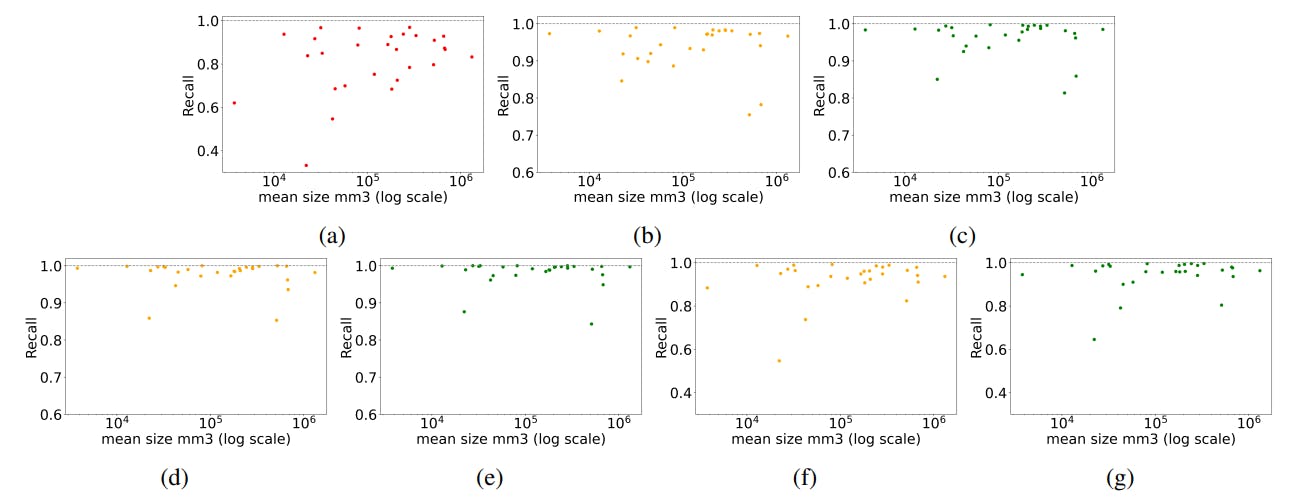
How Pre-Trained Vision Models Are Revolutionizing Anatomical Structure Retrieval
29 Aug 2025
A new benchmark for 3D medical image retrieval shows how pre-trained vision models and ColBERT-inspired methods enhance organ-level search.
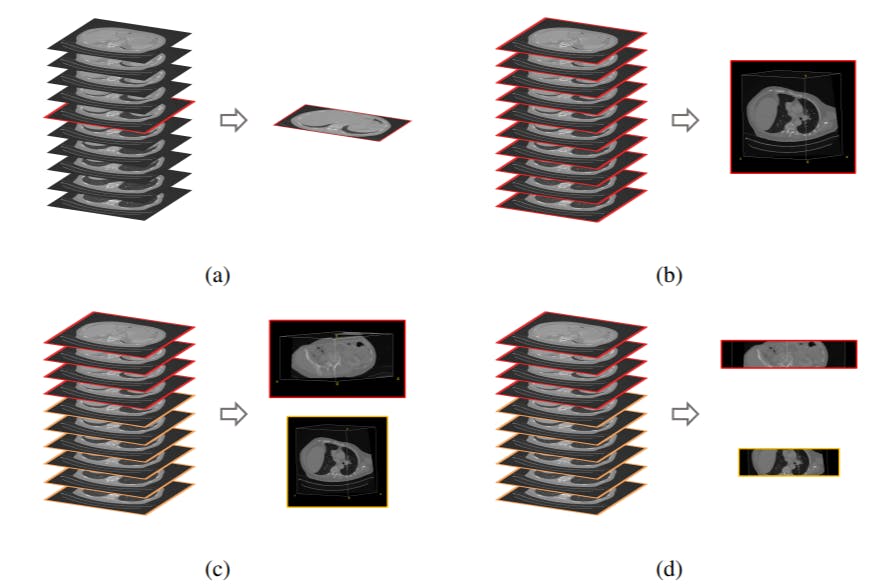
Why One Small Parameter Can Make or Break Your Medical Image Retrieval
29 Aug 2025
Learn how volume-based, region-based, and localized retrieval shape medical imaging accuracy—and why localization-ratio matters.
DreamSim and the Future of Embedding Models in Radiology AI
29 Aug 2025
DreamSim embeddings outperform rivals in medical image retrieval, while fractal-based models show surprising promise for scalable AI training.
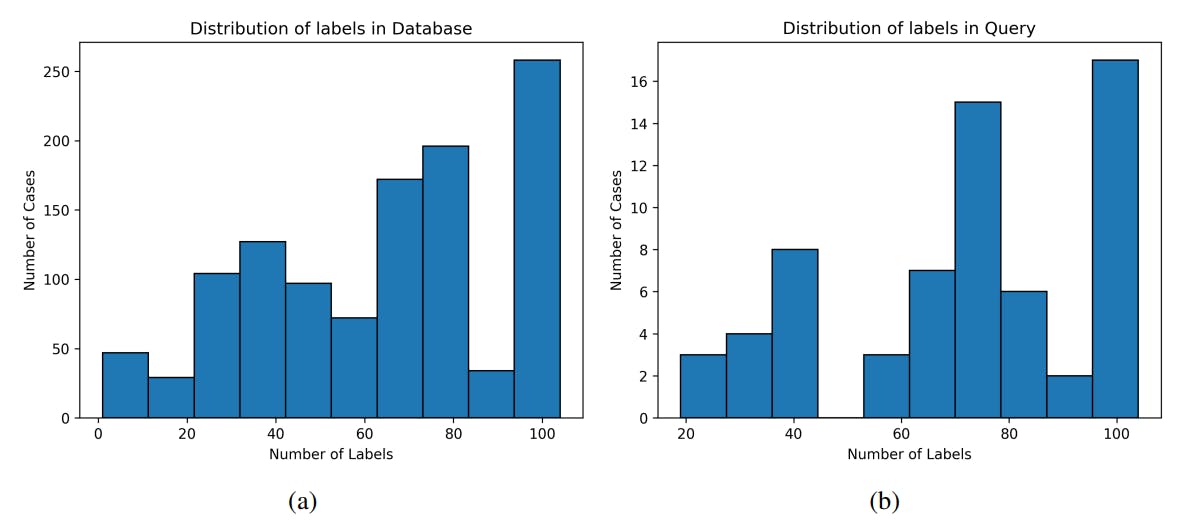
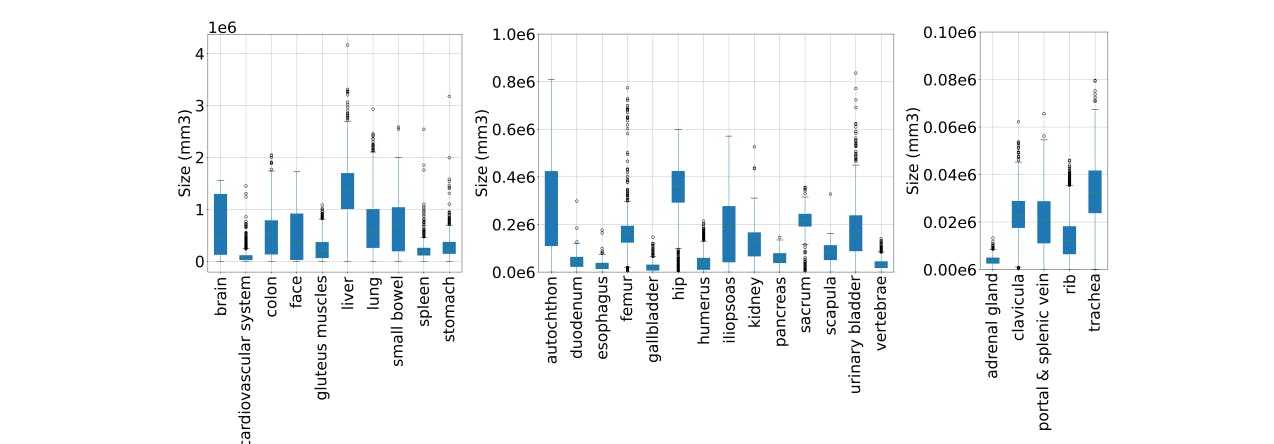
How Dataset Imbalances Shape Medical Image Retrieval Accuracy
29 Aug 2025
Exploring dataset imbalance and ColBERT-inspired re-ranking in medical image retrieval—balancing recall accuracy with real-world feasibility.
Boosting Anatomical Retrieval Accuracy with Re-Ranking Methods
28 Aug 2025
Re-ranking boosts retrieval recall in anatomical AI models, with DreamSim leading performance across volume, region, and localization tasks.

Medical AI Models Battle It Out—And the Winner Might Surprise You
28 Aug 2025
Evaluation of retrieval recall in medical AI—comparing DreamSim, DINO, and ResNet50 across slice-wise, volume, region, and localized methods.